TSF-APM(v1.12.4)
1.基础内容
1.1.整体架构
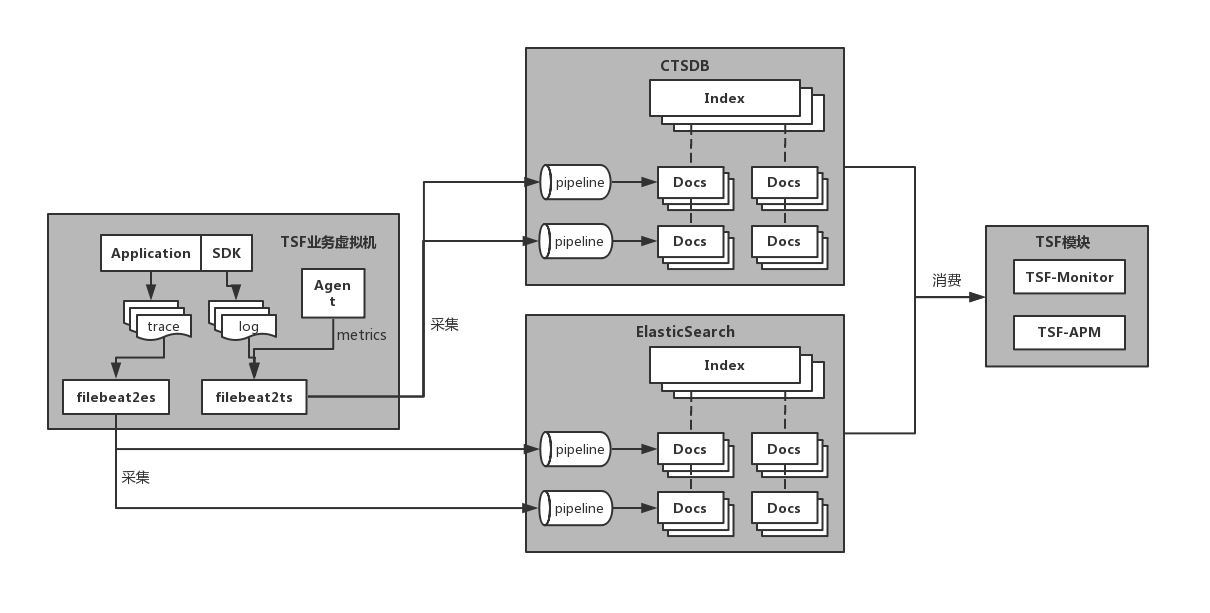
- 数据生产:SDK,产生链路日志、应用日志、监控日志数据
- 数据采集:filebeat2es/filebeat2ts,采集本地日志数据
- 数据存储:ES,存储应用日志数据;TSDB,存储链路日志和监控日志数据
- 数据展示:TSF-APM/TSF-Monitor/TSF-Analyst等
1.2.常用信息
1.2.1.部署路径
- filebeat2es:客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中,$HOME/tsf-agent/filebeat/elasticsearch 路径下
- filebeat2ts:客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中,$HOME/tsf-agent/filebeat/tsdatabase 路径下
- elasticsearch:elasticsearch 集群机器,/data/tsf-elasticsearch/elasticsearch 路径下
- tsdb:tsdb 集群机器,/data/tsf-ctsdb/elasticsearch 路径下
- TSF-APM/TSF-Monitor/TSF-Analyst:TSF 控制台集群机器,$HOME/tsf/tsf-oss 路径下相应模块
1.2.2.日志路径
Linux系统日志:/var/log/message
链路日志:客户环境虚拟机或客户应用容器中,/data/tsf_apm/trace/logs/trace_log*.log
- 应用日志:
- 业务日志:由用户在应用配置文件中设置并填写到TSF控制台日志配置项中,默认为应用启动路径 logs 子目录下
- 标准输出日志:/var/log/tsf/stdout
- 监控日志:
- 调用监控:客户环境虚拟机或客户应用容器中,/data/tsf_apm/monitor/logs/invocation_log*
- 机器指标监控:/var/log/tsf/metric/*
- 采集器日志:
- filebeat2es:客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中,$HOME/tsf-agent/filebeat/elasticsearch/logs/filebeat*
- filebeat2ts:客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中,$HOME/tsf-agent/filebeat/tsdatabase/logs/filebeat*
- 存储集群日志:
- elasticsearch:elasticsearch 集群机器,/data/tsf-elasticsearch/elasticsearch/logs/tsf_es_cluster.log
- tsdb:tsdb 集群机器,/data/tsf-ctsdb/elasticsearch/logs/tsf_ctsdb_cluster.log
- TSF控制台组件日志:TSF 控制台集群机器,/var/log/tsf-oss/tsf-apm(tsf-monitor/tsf-analyst)/*.log
1.2.3.相关链接
- 应用开发文档:
- SDK 下载:https://cloud.tencent.com/document/product/649/20231
- SDK 更新日志:https://cloud.tencent.com/document/product/649/20230
- 链路追踪接入:https://cloud.tencent.com/document/product/649/16622
- 服务监控接入:https://cloud.tencent.com/document/product/649/34294
- Mesh 开发指引:https://cloud.tencent.com/document/product/649/19049
- 容器镜像制作:https://cloud.tencent.com/document/product/649/17007
- 产品使用文档:
2.链路追踪相关问题
2.1.依赖拓扑图查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
2.2.依赖拓扑图查询无结果
(1)确认该【命名空间】下业务应用在【查询时间范围】内发生了相互请求调用
(2)确认相关业务应用均按【开发文档】指示依赖了【TSF Sleuth SDK】
(3)确认【链路日志】正常创建并有日志数据写入,如果为容器部署还需检查日志中 timestamp 字段时间戳与北京时间同步
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2ts
(5)检查采集器 filebeat2ts 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
2.3.调用链列表查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
2.4.调用链列表查询无结果
(1)确认业务应用在【查询时间范围】内发生了相互请求调用
(2)确认相关业务应用均按【开发文档】指示依赖了【TSF Sleuth SDK】
(3)确认【链路日志】正常创建并有日志数据写入,如果为容器部署还需检查日志中 timestamp 字段时间戳与北京时间同步
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2ts
(5)检查采集器 filebeat2ts 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
2.5.链路详情查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
2.6.链路详情查询无结果
(1)获取控制台请求返回详情(参见附录)
(2)提供 RequestID 和返回内容反馈TSF同事协助处理
3.应用日志相关问题
3.1.实时业务日志查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
3.2.实时业务日志查询无结果
注意:控制台实时业务日志与本地业务日志输出间会有15秒左右采集时延
(1)确认业务应用在【查询时间范围】内本地文件产生了业务日志,如果为容器部署还需检查日志中时间字段与北京时间同步
(2)确认业务日志路径按【产品使用文档】指示配置到了【日志配置项】并发布到相关部署组(注:容器部署组发布日志配置后需重启生效)
(3)确认业务日志格式按【产品使用文档】指示正确配置到了【日志配置项】,否则可能导致解析失败无法展示
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2es
(5)检查采集器 filebeat2es 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
3.3.历史业务日志查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
3.4.历史业务日志查询无结果(结果缺失)
(1)确认业务应用在【查询时间范围】内本地文件产生了业务日志,如果为容器部署还需检查日志中时间字段与北京时间同步
(2)确认查询条件按【产品使用文档】指示正确操作,需特别关注排序方式、分词符、短语检索等方面
(3)确认业务日志路径按【产品使用文档】指示配置到了【日志配置项】并发布到相关部署组(注:容器部署组发布日志配置后需重启生效)
(4)确认业务日志格式按【产品使用文档】指示正确配置到了【日志配置项】,否则可能导致解析失败无法展示
(5)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2es
(6)检查采集器 filebeat2es 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(7)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
3.5.实时标准输出日志查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
3.6.实时标准输出日志查询无结果
注意:控制台实时标准暑输出日志与本地标准输出日志输出间会有15秒左右采集时延
(1)确认业务应用在【查询时间范围】内本地文件产生了标准输出日志,如果为容器部署还需检查日志中时间字段与北京时间同步
(2)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2es
(3)检查采集器 filebeat2es 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(4)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
4.监控统计相关问题
4.1.概览页查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
4.2.概览页查询无结果
(1)确认业务应用在指定【命名空间】的【查询时间范围】内发生了服务间调用(可通过依赖拓扑辅助确认)
(2)确认业务应用根据【应用开发文档】正确添加了【TSF 监控 SDK】
(3)确认【调用监控日志】正常创建且日志正常写入,如果为容器部署还需检查日志中时间戳与北京时间同步
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2ts
(5)检查采集器 filebeat2ts 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
4.3.服务监控查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-apm 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-apm 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-apm
(5)打开 tsf-apm 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
4.4.服务监控查询无结果
(1)确认业务应用在指定【命名空间】的【查询时间范围】内发生了服务间调用(可通过依赖拓扑辅助确认)
(2)确认业务应用根据【应用开发文档】正确添加了【TSF 监控 SDK】
(3)确认【调用监控日志】正常创建且日志正常写入,如果为容器部署还需检查日志中时间戳与北京时间同步
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2ts
(5)检查采集器 filebeat2ts 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
4.5.服务统计查询出错
(1)获取控制台出错请求 RequestID 和详情(参见附录)
(2)如果错误详情包含【请求参数错误】或【业务逻辑错误】等具体错误原因,可根据错误原因自行排查,或反馈TSF同事协助排查
(3)如果错误详情为【内部服务错误】或【暂时无法响应请求】,则需登录到 tsf-analyst 部署机器(多机部署则各机器同样操作排查)继续排查
(4)使用以下命令确认 tsf-analyst 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-analyst
(5)打开 tsf-analyst 组件对应时间段日志,使用 RequestID 查找错误原因
(6)错误原因为访问 elasticsearch/tsdb 403错误,可参考【后端组件相关问题】排查处理,其他原因可反馈TSF同事协助处理
4.6.服务统计查询无结果
(1)确认业务应用在指定【命名空间】的【查询时间范围】内发生了服务间调用(可通过依赖拓扑辅助确认)
(2)确认业务应用根据【应用开发文档】正确添加了【TSF 监控 SDK】
(3)确认【调用监控日志】正常创建且日志正常写入,如果为容器部署还需检查日志中时间戳与北京时间同步
(4)确认采集器正常:登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中使用以下命令确认。若异常可反馈TSF同事协助处理
ps -ef | grep filebeat2ts
(5)检查采集器 filebeat2ts 日志是否有 Error 信息,如果存在 403 相关信息,可参考【后端组件相关问题】排查处理
(6)登录到 tsf-analyst 部署机器(多机部署则各机器同样操作排查)使用以下命令确认 tsf-analyst 进程正常,若进程异常可反馈TSF同事协助处理
ps -ef | grep tsf-analyst
(7)打开 tsf-analyst 组件日志,查看是否有 ERROR 日志信息
(8)上述问题均检查无误,可收集控制台出错请求 RequestID 和以上排查信息反馈反馈TSF同事协助处理
4.7.服务实例/应用/部署组监控曲线异常
(1)从运营端页面检查 tsf-monitor、tsf-metrics、es、ctsdb 模块是否正常运行。
(2)进入到以上模块的机器内使用 ps aux | grep [进程名] 查看相关进程是否存在。
(3)检查运营端【参数配置】栏,barad.report.log.url、barad.report.trace.url、barad.report.event.url是否配置正确;独立版环境则指向 tsf-metrics 模块所在的实例地址;公有云环境则参考参数示例一栏。
(4)如果上述三个参数配置正确, 则判断是不是在一键部署之后修改成正确的, 如果是则重启 tsf-monitor、tsf-ratelimit-master 模块。
(5)检查 tsf-monitor、tsf-metrics 模块日志的异常信息。
5.后端组件相关问题
5.1.ES/TSDB 集群异常
(1)检查集群健康状态:登录ES/CTSDB集群任一机器,使用以下命令查看
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cluster/health?pretty
- status:集群状态:Green(正常);Yellow(备份数据不可用,不影响正常工作);Red(主备数据不可用,影响正常工作)
- number_of_nodes:集群节点数,应与实际启动的集群节点数相等
(2)集群 Red / Yellow 异常
可以查看集群各个节点日志和系统日志确认故障原因
确认集群各个节点是否正常运行
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cat/nodes?v如果有节点缺失:
- 登录该节点机器
- 切换至c_log用户
- 进入ES/TSDB部署路径 bin 子目录
- 执行 ./elasticsearch -d 命令重启节点
所有节点启动后,集群自动开始恢复数据分片分配,可通过健康检查命令确认恢复进度:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cluster/health?pretty返回结果如下:
{ "cluster_name": "clog_qcloud_gz", "status": "green", "timed_out": false, "number_of_nodes": 99, "number_of_data_nodes": 99, "active_primary_shards": 8504, "active_shards": 17018, "relocating_shards": 60, # 重点关注:正在进行搬迁的shard数 "initializing_shards": 0, # 重点关注:正在初始化的shard数 "unassigned_shards": 0, # 重点关注:未分配的shard数 "delayed_unassigned_shards": 0, "number_of_pending_tasks": 39, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 80643, "active_shards_percent_as_number": 100 # 重点关注:已恢复分片百分比 }如果发现未分配shard数量过多或恢复百分比提升较慢,可以适当调整集群恢复速度,待集群恢复后再调整为原值。集群并发恢复设置如下:
// 调大恢复速度 curl -u root:changeme -XPUT http://127.0.0.1:9200(ctsdb:9201)/_cluster/settings -d '{ "persistent": { "cluster.routing.allocation.node_concurrent_recoveries": 56, "indices.recovery.max_bytes_per_sec": "400mb" } }' // 调回原来的值 curl -u root:changeme -XPUT http://127.0.0.1:9200(ctsdb:9201)/_cluster/settings -d '{ "persistent": { "cluster.routing.allocation.node_concurrent_recoveries": 8, "indices.recovery.max_bytes_per_sec": "40mb" } }'极端情况下,对于集群无法自动分配恢复的shard,可通过手动执行分配。首先通过以下命令查看这些未分配的shard:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cat/shards?v找到状态为 UNASSIGNED 的 shard 执行手动分配,命令如下:
curl -u root:changeme -XPOST http://127.0.0.1:9200(ctsdb:9201)/_cluster/reroute?retry_failed=true -d '{ "commands": [{ "allocate_stale_primary": { "index": "${index_name}", # shard所在的index "shard": 1, # shard号 "node": "${node_name}", # 分配到哪个node上 "accept_data_loss":true # 是否接受数据有丢失 } }] }' 例如: curl -XPOST localhost:9200/_cluster/reroute?retry_failed=true -d '{ "commands": [{ "allocate_stale_primary": { "index": "vpc_ping_detail-60@57600000_99", "shard": 1, "node": "1503496474000001709", "accept_data_loss":true } }] }'
5.2.ES/TSDB 集群访问超时
(1)确认到 ES/TSDB 集群的网络连通性,排除因网络问题导致的请求超时
(2)确认集群健康状态,可参考【ES/TSDB 集群异常】排查
(3)确认集群节点负载,可通过以下命令查看(间隔数秒多次请求查看趋势):
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cat/nodes?v
主要关注指标:
- heap.percent:堆内存使用率,平均超过70%表明资源紧张
- cpu:CPU使用率,平均超过70%表明资源紧张
- load_1m/load_5m/load_15m:节点负载,平均超过10表明资源紧张
(4)如果堆内存使用率过高,可通过以下方法临时处理:
清理 fielddata cache:在 text 类型的字段上进行聚合和排序时会使用 fileddata 数据结构,可能占用较大内存。可以通过以下命令查看索引的 fileddata 内存占用:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cat/indices?v&h=index,fielddata.memory_size&s=fielddata.memory_size:desc若 fielddata 占用内存过高,可以使用如下命令清理 fielddata:
curl -u root:changeme -XPOST http://127.0.0.1:9200(ctsdb:9201)/${fielddata占用内存较高的索引}/_cache/clear?fielddata=true清理 segment:每个 segment 的 FST 结构都会被加载到内存中,并且这些内存是不会被 GC 回收的。因此如果索引的 segment 数量过大,也会导致内存使用率较高。可以使用如下命令查看各节点的 segment 数量和占用内存大小:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_cat/nodes?v&h=segments.count,segments.memory&s=segments.memory:desc若 segment 占用内存过高,可以通过删除部分不用的索引,关闭索引临时降低集群负载:
// 临时关闭指定日志的索引数据 curl -u root:changeme -XPOST 'http://127.0.0.1:9200(ctsdb:9201)/tsf-*@2019-06-06*/_flush' curl -u root:changeme -XPOST 'http://127.0.0.1:9200(ctsdb:9201)/tsf-*@2019-06-06*/_close' // 清理指定日志的索引数据 curl -u root:changeme -XDELETE 'http://127.0.0.1:9200(ctsdb:9201)/tsf-*@2019-06-06*' -s
(5)如果上述操作后仍出现访问超时问题,说明您的集群规模已经不匹配于您的业务负载,需要扩大集群规模
5.3.控制台访问 ES/TSDB 集群 Authentication not allowed/403 错误
(1)登录ES/CTSDB集群任一机器,使用以下命令查看白名单配置(注意ES/CTSDB端口不同):
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_auth/hosts?pretty
(2)确认TSF OSS和TSF CAE Controller服务机器IP已经添加到白名单:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_auth/hosts?pretty
(3)如果没有则使用以下命令添加:
curl -u root:changeme -XPOST http://127.0.0.1:9200(ctsdb:9201)/_auth/host/<host-ip>
(4)确认白名单已添加,若控制台请求正常,处理结束;否则需根据ES/CTSDB日志继续排查;
(5)确认ES/CTSDB日志“forbidden request”相关报错日志中“OA”字段的IP地址是否为已配置为白名单的IP。如果未在白名单中,首先确认是否是遗漏未配置为白名单的SF OSS和TSF CAE Controller服务机器IP,再确认该IP是否为VIP服务IP且VIP服务是否配置为使用原始IP访问后端服务;附:F5 VIP重要配置说明参考:https://blog.csdn.net/tiwerbao/article/details/45850471;https://blog.51cto.com/i6313/1896312
(6)确认非上述权限问题,可参考【ES/TSDB 集群异常】和【ES/TSDB 集群访问超时】部分排查处理
5.4.采集器写入 ES/TSDB 集群 Authentication not allowed/403 错误
(1)登录客户环境虚拟机或与客户应用容器同 Pod 部署的 TSF Agent 容器中,进入采集器部署路径,获取采集器账户信息(filebeat.yml 配置文件中的username字段):
output.elasticsearch:
hosts: ["xxx.xxx.xxx.xxx:9201"]
username: "tsf-es-xxxxxx"
password: "xxx"
pipeline: "%{[fields.pipename]}"
(2)登录ES/CTSDB集群任一机器,使用以下命令查看账户列表:
curl -u root:changeme -XGET http://127.0.0.1:9200(ctsdb:9201)/_auth/users?pretty
(3)如果采集器账户未出现在账户列表中,则可能存在时序数据库重装导致权限数据丢失,可反馈TSF运维同事协助处理
(4)确认非上述权限问题,可参考【ES/TSDB 集群异常】和【ES/TSDB 集群访问超时】部分排查处理
5.5.磁盘空间不足导致ES/TSDB集群异常
(1)确认集群服务器上ES进程或时序数据库进程、kibana进程是否运行,相关命令:
#查看es进程
ps -ef | grep tsf-elasticsearch
#查看TSDB进程
ps -ef | grep tsf-ctsdb
#查看es Kibana进程
netstat -apn | grep 5601
#查看TSDB Kibana进程
netstat -apn | grep 5602
如果进程不存在或部分存在,执行步骤(2);否则执行步骤(4);
(2)尝试重启退出的进程,优先在运营平台上操作,相关命令(注意:在确认ES/TSDB集群启动后再启动对应kibana服务):
#若环境用root用户部署
#切换到c_log用户
su c_log
#以c_log用户启动ES进程
cd /data/tsf-elasticsearch/elasticsearch/bin
./elasticsearch -d
#以c_log用户启动TSDB进程
cd /data/tsf-ctsdb/elasticsearch/bin
./elasticsearch -d
#以c_log用户启动Kibana进程
cd /data/tsf-kibana/kibana/binnohup ./kibana 2>&1 &
#若环境用非root用户部署
#启动ES进程
cd /data/tsf-elasticsearch/elasticsearch/bin
./elasticsearch -d
#启动TSDB进程
cd /data/tsf-ctsdb/elasticsearch/bin
./elasticsearch -d
#启动Kibana进程
cd /data/tsf-kibana/kibana/binnohup ./kibana 2>&1 &
再次确认进程是否正常启动,如果还是无法正常启动,执行步骤(3),否则执行步骤(4);
(3)确认进程启动异常原因:对于ES或TSDB集群节点,可以先通过前台运行方式(./elasticsearch方式启动不指定-d参数)查看异常原因;对于kibana进程可以查看启动日志(/data/tsf-kibana/kibana/logs目录下)。通常会由于磁盘空间不足(no device space)导致集群无法启动进而导致kibana服务无法启动。此时需先手动清理部分索引数据后再执行步骤B启动服务。手动清理步骤:
#进入机器上集群节点的索引数据目录(?表示集群中节点的序号)
cd /data/tsf-elasticsearch/elasticsearch/data/nodes/?/indices
#查看索引子目录大小和时间
ls -ldu -h --max-depth=1
#选择较旧较大的子目录,记住子目录名字符串,在集群所以节点上均删除该子目录
rm -rf hfeuHEHOnfw...fesre
#清理完成后,确认集群所有节点/data路径下均留有至少10G空间
df -h
如果手动清除后仍然无法启动进程或由于非磁盘空间原因导致进程无法启动,集定位流程中的相关信息截图发送给TSF运维同事协助处理;否则,继续执行步骤(4);
(4)通过浏览器访问集群Kibana服务,选择开发工具,在控制台(Console)执行以下命令确认集群基本状态:
#查看集群健康状态
GET _cluster/health?pretty
#查看集群各节点可用空间
GET _cat/nodes?v&h=id,ip,disk.avail
如果节点可用空间少于总空间的30%(建议值,具体需要根据环境中数据产生速度确定),可通过以下命令进一步清理集群中的旧数据:
#查看集群中索引列表
GET _cat/indices?v
#删除指定日期的索引数据
DELETE /tsf-*@2018-12-25*
确认磁盘空间充足后,等待集群进行自动恢复。此阶段可以隔一分钟刷新查看集群状态,主要关注unassigned_shards(未分配分片数量)和active_shards_percent_as_number(活动分片百分比)。如果未分配数量持续减少、活动分片百分比持续增加直至100%,集群状态字段显示green,说明集群恢复完成,处理结束;否则,如果存在部分分片一段时间后仍未自动分配,则执行步骤E进行手动分配;
(5)首先确认未分配的分片的索引和分片号:
#查看集群中的分片列表
GET _cat/shards?v
找到状态(state)为unassign的分片,确认其索引名(index)、分片值(shard)、主备属性(prirep),执行手动分配操作:
首先对于主分片(主备属性为p)进行处理,命令如下(其中node-ip为集群中任一节点IP):
POST _cluster/reroute?retry_failed=5&pretty
{ "commands" : [ {
"allocate_stale_primary" : {
"index" : "myindex",
"shard" :myshard,
"node" : "node-ip",
"accept_data_loss" : true
}
}]
}
执行完命令后等待集群处理,再次确认集群中是否存在未分配的主分片,如果所有集群中主分片都重分配后仍存在未分配的备分片导致活动分片百分比不为100%,则通过以下命令处理备分片(其中node-ip为集群中任一节点IP):
POST _cluster/reroute?retry_failed=5&pretty
{
"commands" : [ {
"allocate_replica" : {
"index" : "myindex",
"shard" :myshard,
"node" : "node-ip",
"accept_data_loss" : true
}
}]
}
待所有分片均分配处理完成后,检查集群状态,确认状态(status)为green且活动分片百分比(active_shards_percent_as_number)为100%;